
INSERTAR múltiples filas en SQL Server con una única sentencia SELECT
Creo que con un ejemplo básico se podrá entender mejor la idea, ¿verdad?. ¡Hagamos más legibles y óptimos nuestros scripts de inserción! Hasta la próxima.

Cómo visualizar rápidamente el código de cualquier Stored Procedure
Hoy me gustaría dejaros una forma realmente rápida y eficiente de consultar el código que reside en vuestros queridos procedimientos almacenados.
Lo primero que tenéis que hacer es redirigir la salida del SQL Server Management Studio a "Texto". Para ello podéis usar CTRL+T en el teclado, o pulsar en el icono correspondiente:

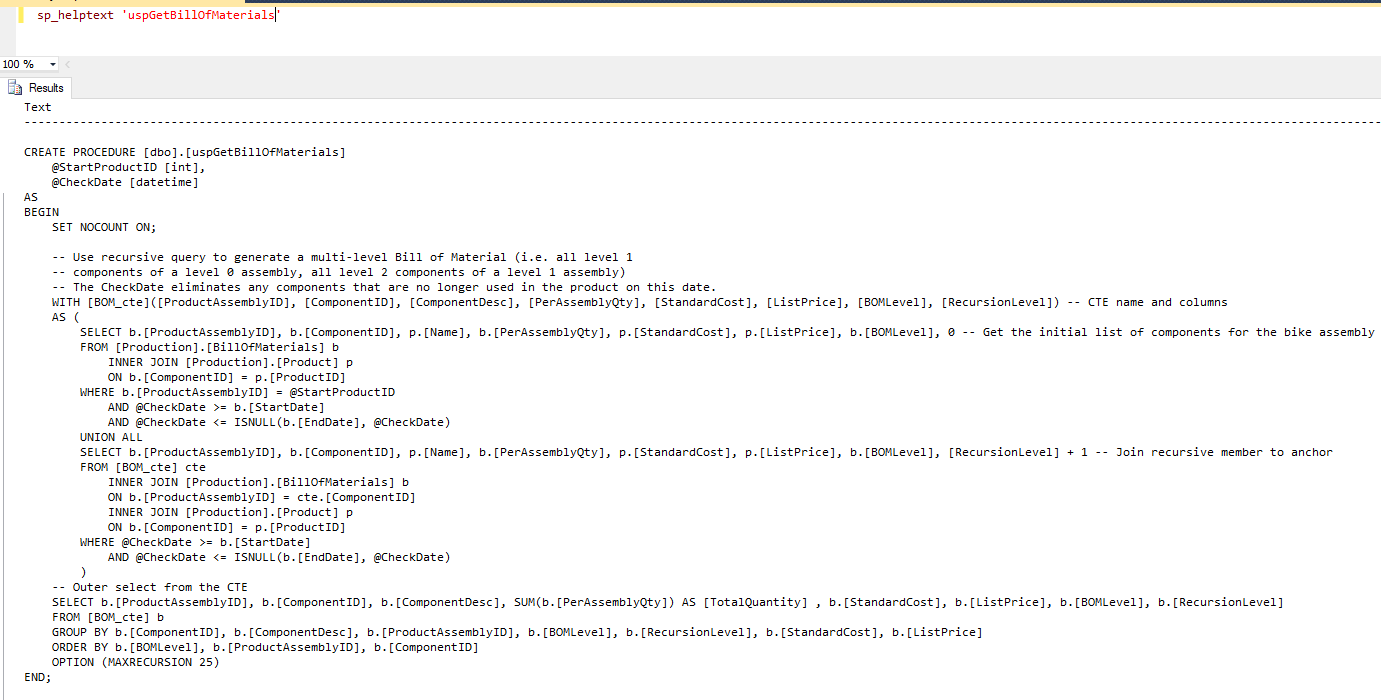
Y ya simplemente ejecutando el comando sp_helptext 'nombre_proc_almacenado' lo tenéis.

Lo primero que tenéis que hacer es redirigir la salida del SQL Server Management Studio a "Texto". Para ello podéis usar CTRL+T en el teclado, o pulsar en el icono correspondiente:

Y ya simplemente ejecutando el comando sp_helptext 'nombre_proc_almacenado' lo tenéis.
Concatenar subconsultas en un único campo en SQL Server
Seguramente os habréis encontrado en situaciones, como yo, en las que teníais que cruzar registros en distintas tablas, y obtener en un único campo el resultado de dicho JOIN, haciendo alguna manipulación "en el camino" sobre algunos o todos los valores "intermedios". Aquí os dejo una sencilla manera de hacerlo, usando una conversión XML "al vuelo". La consulta del ejemplo la lanzo contra la BD AdventureWorks2012 que podéis descargaros aquí.
Básicamente el truco está en tomar los valores del campo que queremos devolver (en el ejemplo sería "Name", el nombre de los departamentos donde cada empleado ha trabajado) en formato XML, que en realidad es una cadena de valores separados por coma, ¡pero añade una al principio!, por lo que debemos eliminarla mediante la sentencia STUFF, que elimina los caracteres indicados en la posición de los primeros argumentos y los reemplaza por el último argumento, en nuestro caso una cadena vacía. Así fácilmente obtenemos lo que queríamos, un listado con todos los empleados y un único campo con todos los departamentos en los que ha trabajado cada uno, ordenados alfabéticamente y separados por coma. ¡Hasta la próxima!

Hadoop: Arquitectura
Comenzamos aquí una serie de posts para presentar, de manera sencilla, clara y breve, las principales características, componentes y arquitecturas relacionadas con los sistemas Big Data actuales. Este primer post versa sobre Hadoop.
Empecemos recordando algunos términos básicos. Un sistema distribuido consta de nodos, donde cada uno de ellos es un ordenador. A un conjunto de nodos almacenados físicamente y conectados en el mismo switch de red, se llama rack. Lógicamente el ancho de banda entre dos nodos de un mismo rack será muchísimo mayor que si están en diferentes racks. Un cluster de Hadoop es una colección de racks.
Hadoop tiene dos principales componentes en su arquitectura:
- HDFS (Hadoop Distributed File System): sistema de ficheros distribuidos
- MapReduce : Framework para realizar operaciones sobre los datos del HDFS
HDFS se ejecuta sobre todos los nodos de un cluster Hadoop, y está diseñado específicamente para gestionar eficientemente replicación de datos, obteniendo así un alto porcentaje de tolerancia a fallos. Hadoop funciona mejor sobre ficheros de gran tamaño ya que así debe gastar menos tiempo en buscar los fragmentos en los discos. Su diseño se beneficia de accesos secuenciales o por streaming, en vez de aleatorios.
Hadoop usa bloques (tamaño por defecto: 64 Mbs, aunque la mayoría de sistemas reales usan 128Mbs o más) para almacenar las partes de un fichero. Estos bloques son de tamaño fijo y esto es una gran ventaja para calcular cuántos se necesitan según lo que ocupan nuestros ficheros, y además es sencillo relativamente situarlos en distintos clusters. Los bloques son replicados en múltiples nodos, asegurando así que si un cluster falla se recupera desde otro cluster. Existen múltiples parámetros de configuración en Hadoop que permiten ajustar eficientemente estas situaciones.
MapReduce se diseñó para procesar enormes conjuntos de datos en entornos distribuidos, usando muchísimos nodos. Como su nombre indica, un programa MapReduce consiste en dos transformaciones básicas, aplicadas a los datos de forma continuada: asignar (Map) y reducir (Reduce).
Pero, ¿qué componentes internos tiene HDFS más concretamente, y cómo usan todos ellos y qué papel juegan, cuando se ejecuta algún MapReduce job?
Podríamos clasificar en HDFS, las siguientes tipologías principales de nodos:
MapReduce se diseñó para procesar enormes conjuntos de datos en entornos distribuidos, usando muchísimos nodos. Como su nombre indica, un programa MapReduce consiste en dos transformaciones básicas, aplicadas a los datos de forma continuada: asignar (Map) y reducir (Reduce).
Pero, ¿qué componentes internos tiene HDFS más concretamente, y cómo usan todos ellos y qué papel juegan, cuando se ejecuta algún MapReduce job?
Podríamos clasificar en HDFS, las siguientes tipologías principales de nodos:
- NameNode : sólo existe uno en el cluster e informa del estado del contenido al resto, ya que contiene los metadatos de los distintos ficheros del cluster. Se recomienda asignarle la máxima RAM posible, para agilizar la gestión de dichos metadatos del sistema.
- DataNode : almacén de Datos. Un típico cluster HDFS tiene muchos DataNodes.
- Secondary NameNode : nodos auxiliares para el NameNode.
- JobTracker : sólo existe uno en el cluster y recibe peticiones de clientes para gestionar las tareas MapReduce en los correspondientes TaskTrackers.
- TaskTracker : nodo donde residen los datos de los jobs y se monitorizan para en caso de fallo, reasignar algún otro TaskTracker. Usan JVMs (máquinas virtuales Java) para correr la tarea de asignación o reducción. Son claves para la ejecución en paralelo de tareas.
- Checkpoint Node : nodos generales de control.
- Backup Node : almacén de copias de seguridad.
Cuando algún proceso cliente inicia una petición, lo atiende un JobTracker, aunque también puede comunicarse directamente con un NameNode o DataNode para recuperar partes de un fichero.
Big Data
Ya hace tiempo vino para quedarse un nuevo término, que a todos los analistas de negocio, ingenieros de datos, en definitiva, a todos los que lidiamos a diario con información (¿no somos todos realmente?), nos atrae, nos confunde, nos apasiona. El Big Data.

¿Pero qué es realmente? Es una plataforma. ¿Sólo eso? No, por supuesto. Es mucho más. Si pensamos en la cantidad de información que se genera por segundo en Internet o en las actividades relacionadas con alguna actividad diaria, como puede ser el tráfico en una ciudad, podemos darnos cuenta que dicho volumen no hace más que crecer: más sensores, más datos, más factores a tener en cuenta, más fuentes de datos, etc. Y la información que viene de dichas fuentes puede venir estructurada, o en la mayoría de las veces, no cuenta con un formato claro. Y ya no nos sirven los tradicionales RDBMS, ni tampoco los modelos de análisis y reporting de antaño, el Online Analytic Processing (OLAP). Ahora, por ejemplo, queremos procesar millones de tweets y posts con las opiniones de nuestros clientes en las Redes Sociales, porque con ello podremos evaluar la satisfacción, la opinión, hacer estimaciones, etc de forma mucho más acertada.
De cómo procesar en tiempo real una información tan masiva de Pentabytes (y creciendo), procedente de múltiples fuentes de datos (que también suelen ir variando conforme pasa el tiempo) y que a la vez nos permite confiar en dichos orígenes, es lo que nos ofrece Big Data, integrando datos variopintos en las operaciones diarias del business, en los data-warehouses, en las aplicaciones, en todos los procesos. Aplicando más analítica sobre más datos, y que éstos serán usados por más usuarios progresivamente.
Las características teóricas subyacentes en Big Data son la famosas 4 V´s: Volumen, Velocidad, Variedad y Veracidad.
Los perfiles de analistas de negocio, ingenieros de datos, etc están evolucionando inexorablemente hacia la nueva profesión: el Data Scientist. El trabajo que haremos en los próximos años, cómo lo haremos y con qué herramientas, nada tendrá que ver con el actual. Con una formación técnica, matemática, mente analítica enfocada a encontrar los problemas verdaderos y cómo resolverlos, será el prototipo de dicho científico. Y también debe estar enfocado al Business porque realmente debe querer aprender y brindar cambios a la organización, proponiendo recomendaciones a sus líderes.
En próximos posts iremos conociendo un poco más en detalle la plataforma Big Data, que entre otros componentes puede incluir, aunque no limitado a ello: Data-warehouses, sistemas de computación en streaming (analizadores de datos generados masivamente por streaming, en tiempo real), y aceleradores (librerías software que nos aportan configuraciones específicas para distintas áreas, como análisis de texto, data mining, servicios financieros, etc).
De cómo procesar en tiempo real una información tan masiva de Pentabytes (y creciendo), procedente de múltiples fuentes de datos (que también suelen ir variando conforme pasa el tiempo) y que a la vez nos permite confiar en dichos orígenes, es lo que nos ofrece Big Data, integrando datos variopintos en las operaciones diarias del business, en los data-warehouses, en las aplicaciones, en todos los procesos. Aplicando más analítica sobre más datos, y que éstos serán usados por más usuarios progresivamente.
Las características teóricas subyacentes en Big Data son la famosas 4 V´s: Volumen, Velocidad, Variedad y Veracidad.
Los perfiles de analistas de negocio, ingenieros de datos, etc están evolucionando inexorablemente hacia la nueva profesión: el Data Scientist. El trabajo que haremos en los próximos años, cómo lo haremos y con qué herramientas, nada tendrá que ver con el actual. Con una formación técnica, matemática, mente analítica enfocada a encontrar los problemas verdaderos y cómo resolverlos, será el prototipo de dicho científico. Y también debe estar enfocado al Business porque realmente debe querer aprender y brindar cambios a la organización, proponiendo recomendaciones a sus líderes.
En próximos posts iremos conociendo un poco más en detalle la plataforma Big Data, que entre otros componentes puede incluir, aunque no limitado a ello: Data-warehouses, sistemas de computación en streaming (analizadores de datos generados masivamente por streaming, en tiempo real), y aceleradores (librerías software que nos aportan configuraciones específicas para distintas áreas, como análisis de texto, data mining, servicios financieros, etc).
Suscribirse a:
Entradas
(
Atom
)