Hoy vamos a repasar algunos de los conceptos básicos referentes a los índices en SQL Server, pero no por ello menos importantes. De hecho os aseguro que uno de los principales motivos de pobre rendimiento en una base de datos es una mala planificación e implantación de los índices en las tablas. ¿Cuándo crearlos? ¿Sobre qué campos crearlos?. ¿Qué tipos de índices puedo declarar?. ¿Mejor sobre un campo o sobre varios?. Son preguntas típicas que vamos a intentar dar respuesta ahora mismo. Lo primero, creamos una sencilla tabla, inicialmente sin ningún tipo de índice. La idea es comparar el rendimiento de una consulta grande (recuperar 1.000.000 de registros) en distintas situaciones: sin índices, con índices non-clustered, con índices clustered, con índices que incluyan (include) a su vez otros campos, etc. Tras estudiar cada caso os recomiendo borrar la tabla (truncate table T_Ejemplo), crearla de nuevo con la correspondiente configuración sobre los índices y volver a insertar los registros.
CREATE TABLE T_Ejemplo (
ID INT,
Nombre VARCHAR(100),
Apellidos VARCHAR(100),
Ciudad VARCHAR(100)
)
GO
INSERT INTO T_Ejemplo(ID,Nombre,Apellidos, Ciudad)
SELECT TOP 1000000 ROW_NUMBER() OVER (ORDER BY a.NAME) RowID,'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.NAME)%2 = 1 THEN 'Cane' ELSE 'Brown' END,
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.NAME)%10 = 1 THEN 'Garcia'
ELSE
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.NAME)%10 = 5 THEN 'Vettel'
ELSE
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.NAME)%10 = 3 THEN 'Fernandes'
ELSE 'Houston' END
END
END
FROM SYS.ALL_objects a CROSS JOIN SYS.ALL_OBJECTS B
GO
La query que en cada caso vamos a estudiar su Plan de Ejecución en el Analizador de Consultas es:
select * from T_Ejemplo WHERE ID BETWEEN 1 AND 1000000
Caso 1: SIN ÍNDICES
 |
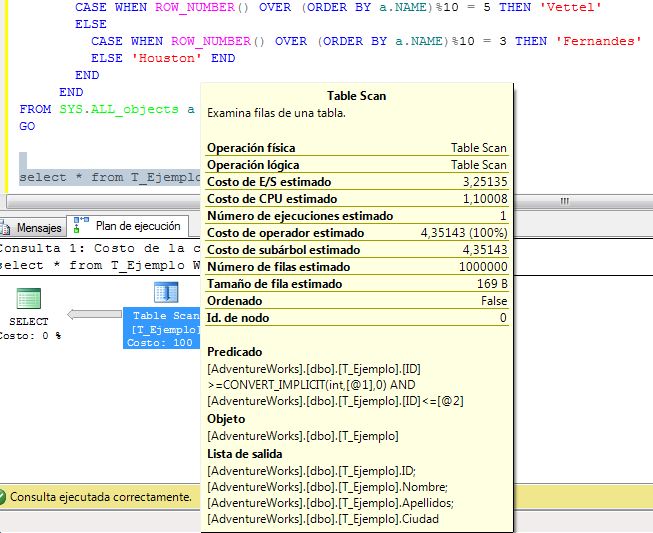
Caso 2: ÍNDICES NONCLUSTERED
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_ID] ON [dbo].[T_Ejemplo] (
[ID] ASC) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Nombre] ON [dbo].[T_Ejemplo] (
[Nombre] ASC) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Apellidos] ON [dbo].[T_Ejemplo (
[Apellidos] ASC) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Ciudad] ON [dbo].[T_Ejemplo] (
[Ciudad] ASC) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_ID_Ciudad] ON [dbo].[T_Ejemplo] (
[ID] ASC,
[Ciudad] ASC
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Nombre_Apellidos] ON [dbo].[T_Ejemplo] (
[Nombre] ASC,
[Apellidos] ASC
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Nombre_Ciudad] ON [dbo].[T_Ejemplo] (
[Nombre] ASC,
[Ciudad] ASC
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_T_Ejemplo_Apellidos_Ciudad] ON [dbo].[T_Ejemplo] (
[Apellidos] ASC,
[Ciudad] ASC) ON [PRIMARY]
GO
En este segundo caso aunque creemos este conjunto de índices, el rendimiento de la consulta es igual (más bien peor) que sin índices. Al insertar los registros puede notarse que el tiempo ha sido muy superior, por el motivo de tener que actualizarse la información de los índices en cada insert (igual para los updates, etc). Si pensamos en forzar el índice sobre el campo ID en la consulta obtenemos ésto:
SELECT * FROM
T_Ejemplo WITH(INDEX([IX_NonClusteredIndex_ID]))
WHERE ID BETWEEN 1 AND 1000000


Conclusión: mala idea el crear este índice para este propósito, y lo vemos claramente al forzar en la query, es por eso por lo que el motor de base de datos no lo usaba antes y ejecutaba la consulta como si no tuviera ningún índice. El rendimiento por tanto, con sólo este índice, es aún peor.
Caso 3: ÍNDICES CLUSTERED
CREATE CLUSTERED INDEX [IX_ClusteredIndex_ID] ON [dbo].[T_Ejemplo] (
[ID] ASC ) ON [PRIMARY]
GO
La inserción de los registros tras crear este único índice clustered, es inmediata, de forma parecida a como si no tuviéramos ningún índice. Veamos el plan de ejecución:

En el escenario propuesto, esta solución es la más eficiente.
Caso 4: ÍNDICES CON COLUMNAS INCLUDE
Para consultas importantes que requieran devolver una serie de campos, filtrando dichas consultas por otra serie de campos, es recomendable crear índices nonclustered que "cubran" a esas consultas, es decir que con los campos a indexar en la condición se incluyan los campos que se devolverán. Veamos un ejemplo:
CREATE NONCLUSTERED INDEX [IX_NonClusteredIndex_ID_Include_Fields] ON [dbo].[T_Ejemplo](
[ID] ASC ) INCLUDE (Nombre, Apellidos, Ciudad) ON [PRIMARY]
GO

Y por tanto el rendimiento se ve claramente mejorado (para la consulta que nos ocupaba, claro). Así que el diseño de los índices debe hacerse en base a la experiencia y conocimiento de las consultas que se van a lanzar al motor. Este es un trabajo cíclico, que conforme aparecen nuevas consultas, sobre todo si son costosas, nos obliga como DBAs a revisar los índices afectados, crear nuevos en su caso, o eliminar los que no se usen. Hasta la próxima.
No hay comentarios :
Publicar un comentario